
It's March 2026 and it's time to revisit a topic I discussed a couple of years back around prompt tone directly impacting the content of the response. A lot has changed in the last couple of years so I thought this would be a good time to update my observations.
Modern LLMs are now very good at code-switching and they know they're doing it, so now answers that seem too memetic may result in a valid answer as well as include half-breaks to the fourth wall in its response. The models now can perform the tonal shift as part of their answer rather than simply responding only in that lingo which can be its own kind of fun but harder to demonstrate.
I'll also point out that more than ever a skilled prompt writer should hopefully have some limited knowledge of the domain they are working in in order to increase the chance of recognizing a failure.
Additionally, richer context in a question may encourage the model to dig deeper (think longer) for better aligned answers. For demonstration I have two examples where the question is basically what's the best character to play in a game.
In the first prompt we see a simple question of "Who's the best character to play in Overwatch?", To which the model responds quickly suggesting an all-around character pick.
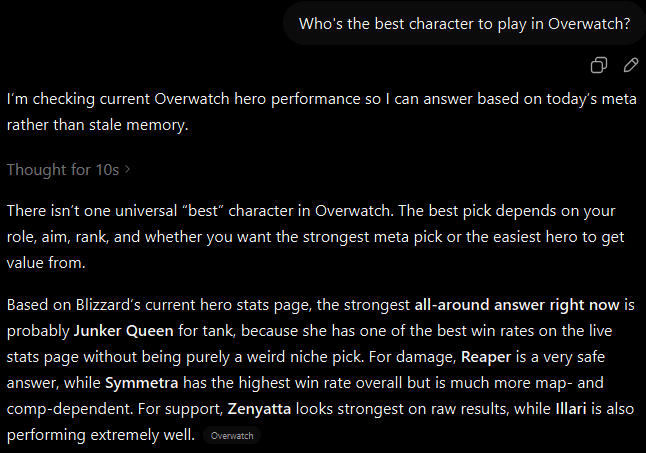
When the question is presented in the tone of a player familiar with the game, the answer produced is far more nuanced and includes game statistics to support the character suggestion.
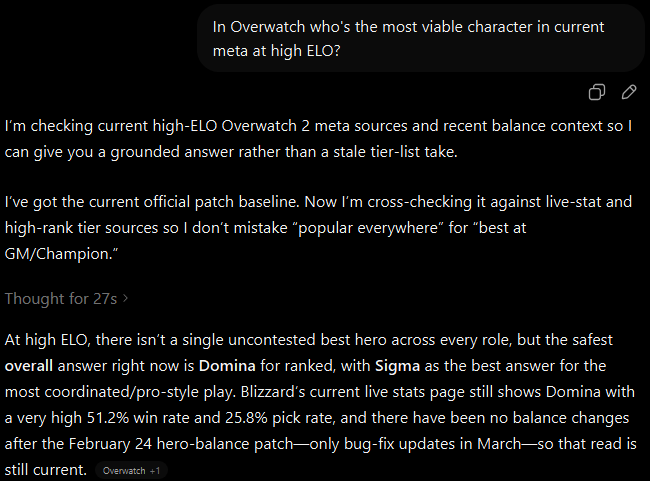
These days, when asking questions on detailed but potentially common concepts that need detailed replies it's become more valuable to load as much context into the prompt as reasonable to help focus the model on the context space most related to the information you present. When you then combine that level of detail with contextual tone you can in many cases improve the detail of the response significantly.
Granted you can go too far the other direction. Too much detail that's too niche in context may not have a sizable enough sample set to produce a meaningful answer, and this is the place where you're going to see anything from failure acknowledgement to flat out hallucinations in the response.
Good luck with your prompting.